
AI についてしっかり説明しようとすると日が暮れてしまいますが、非エンジニアの方に向けて「ざっくり」と解説しようと試みた記事です。
AI と一口に言っても、その技術は多岐にわたります。
それらを総称して「 AI 」と呼んでいます。
しかし、この説明は学者先生によっても定義が違うため、一部は主観が入ることをご理解ください。
また、Pythonは AI と親和性があるため、その辺のカンケイについても少し紹介します。
あまり期待はしないで読み進めてください。
あくまで、「ざっくり」ですよ。ざっくり(笑)
身近で使われている AI 技術
「これって AI の技術だよねー」と認識しながら利用しているものもあれば、「これって AI で動いてんの!?」とビックリする場面もあります。
代表的なもの、面白いものをまとめてみました。
- スマホの音声認識 「Siri、Googleアシスタントなど」
- メルカリ 「商品画像から商品名を検索、違反検知など」
- お掃除ロボット 「ルンバ」
- 自動車 「自動運転、衝突回避」
- 洗濯機 「選択の量と汚れを判断して選択する」
- Amazon 「レコメンド(おすすめ商品)」
- 無人コンビニ 「TOUCH TO GO、Amazon Goなど」
- 自動応答のチャットボット 「Microsoftのりんな、企業のサポート」

他にも、エアコンや電子レンジや冷蔵庫、、、いろいろな家電に「 AI 」が搭載されてきました。
AI の歴史
さて、AI という言葉はいつ頃から聞いていますか?
「割と最近だよね?」と感じている方も多いかもしれません。
しかし、実は AI という概念自体は1950年代から存在します。
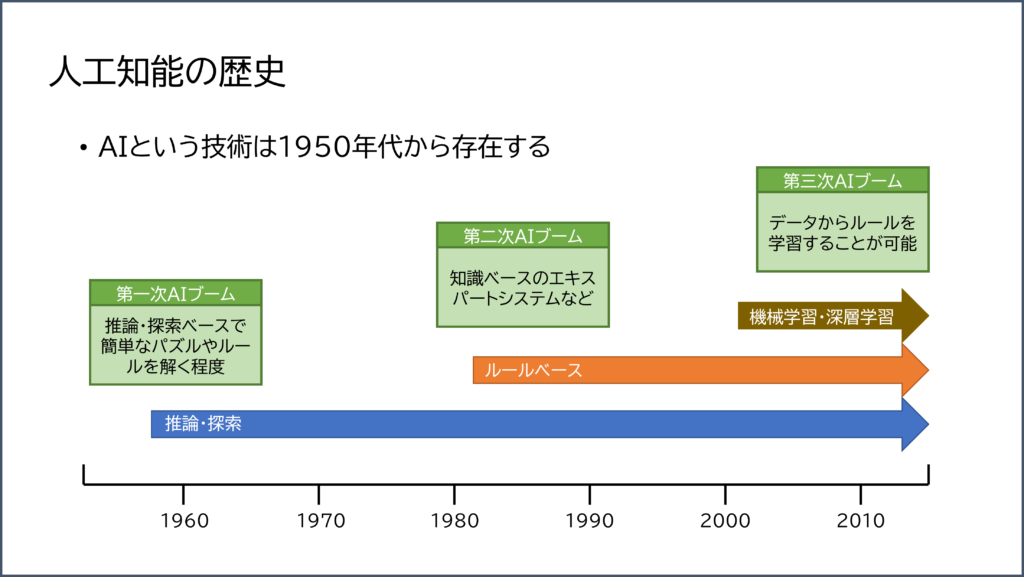
もちろん、1950年代の AI は現在の AI とはほとんど別物で、いわゆる推論や探索をプログラムにしたものを AI と呼んでいました。
その後、1980年代には知識(ルール)ベースのエキスパートシステムというものが流行りますが、盛り上がりに欠けました。
そして、私たちに最もなじみ深い AI となるのが現在の「機械学習(マシンラーニング)」や「深層学習(ディープラーニング)」と呼ばれる AI 技術になります。
なぜ AI が盛り上がったのか?
結構昔から存在する AI 技術(という考え方)ですが、なぜ2000年以降にこれほど盛り上がったのか?
それには3つの理由があります。
理由①インターネットの普及とビッグデータ

アナログ通信からISDN、ADSLから光回線と、インターネット通信の環境はどんどん早く、安くなりました。
また、2008年頃からスマホが普及し、現在に至るまで個人のデータがどんどん蓄積され、いわゆるビッグデータが利用されるようになりました。
データが増えると、そのデータを利用するための技術も普及します。
AI 技術では、データを学習するために大量のデータが必要となるので、ビッグデータが必須となります。
また、LINEやTwitter、天気情報など、様々なサービスが提供する情報をアプリケーション側で受け取れるAPIという仕組みも充実してきたことも理由の一つと考えます。
理由②高度な計算処理が可能なPCの普及

個人が所有するレベルのPCのスペックが格段に上がってきました。
昔は超大型コンピュータが必要だったのに、現在は個人のノートPCでも高速・大容量となりました。
また、グラフィックを処理するGPUも多くのPCに搭載されています。
さらに、個人のPC以外に、AWSやGCP、Azureなどクラウドサービスも充実し、誰でもスーパーコンピュータ並みの処理を行うことが可能となりました。
理由③AI 関連のライブラリが充実

Pythonが注目され始めた理由の一つでもありますが、いわゆる AI 関連のライブラリが充実しています。
そのほとんどはオープンソースで開発されており、無料で利用できます。
また、それらのライブラリを利用することで、数学やアルゴリズムを理解せずとも AI のアプリケーションが開発できるようになりました。
PythonのAI関連ライブラリについて、こちらの記事もご覧ください。

現在はどんどん新しい AI 関連のライブラリが出ており、すべてを追いかけるのは無理になりました(笑)
僕はもともと専門ではありませんが、2年前の技術(ライブラリ)で止まっています。
人工知能関連技術の全体像
細かい話は抜きにして、いわゆる AI 技術の全体を図解します。
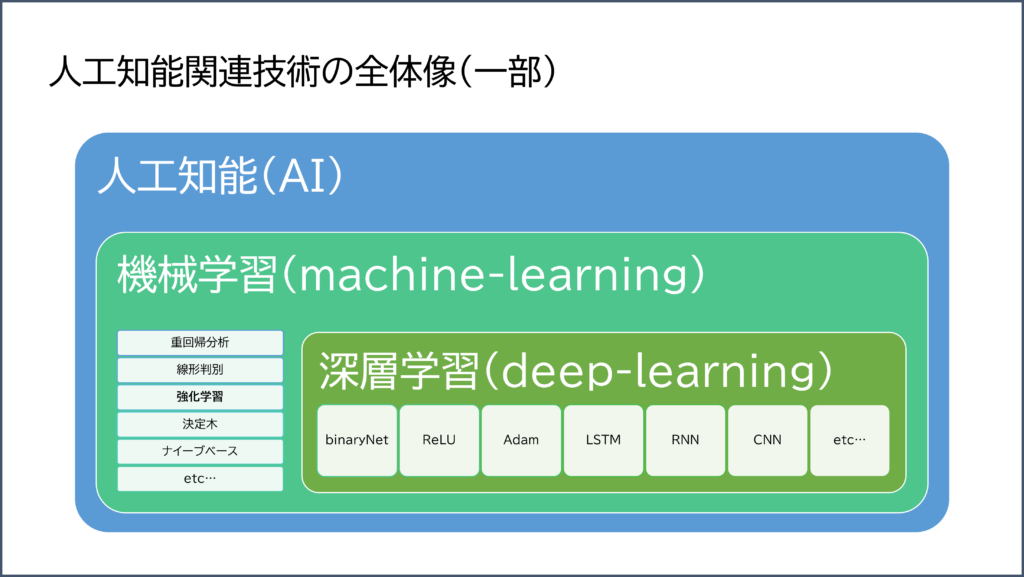
それぞれアルゴリズムの一部を掲載していますが、専門でなければさっぱりだと思うので分からない人は無視してください。
AI 関連技術の言葉の定義
上記の図のうち、人工知能、機械学習、深層学習という言葉の定義を簡単にまとめました。
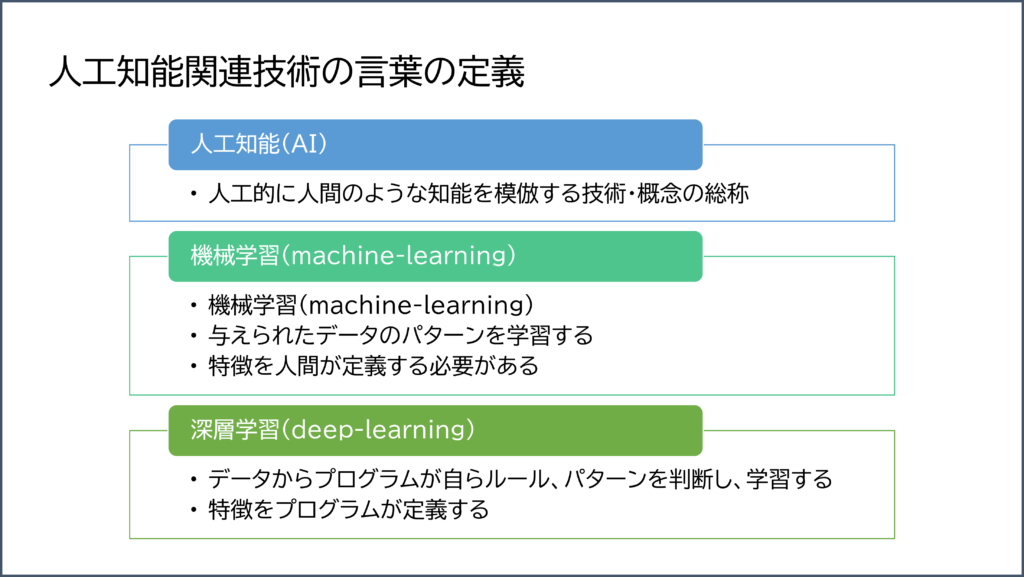
いわゆる「 AI 」というのは全体の概念であって、実際の「人工知能の技術」としては「機械学習」や「深層学習」またはその組み合わせとなる「深層強化学習」などさまざまに存在します。
要は、
- 機械学習:人間がデータを用意してルールを決めたものをプログラムが学習する
- 深層学習:データを与えるとプログラムが必要な学習をする
という違いです。
その中でも、目的に応じてアルゴリズムを使い分けることになります。
(分類したいのか、回帰したいのか、予想したいのか、など。)
機械学習の仕組み
AI 技術の中でも、機械学習についての仕組みを少し詳しくご紹介します。
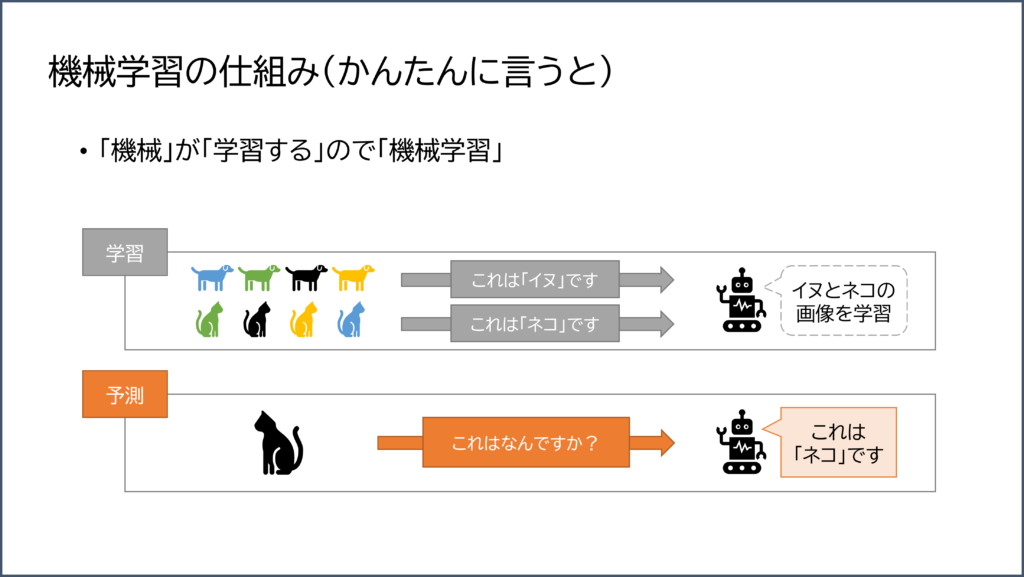
図の通り、「学習」と「予測」のプログラムは別のものとなります。
学習した結果、そのルール(モデル)を作成し、予測するプログラムで利用します。
この時、データと簡単に言いますが、この「データ」を用意するのが大変なのです!!!
機械学習の「前工程」
そのデータを準備する過程を簡単に説明します。
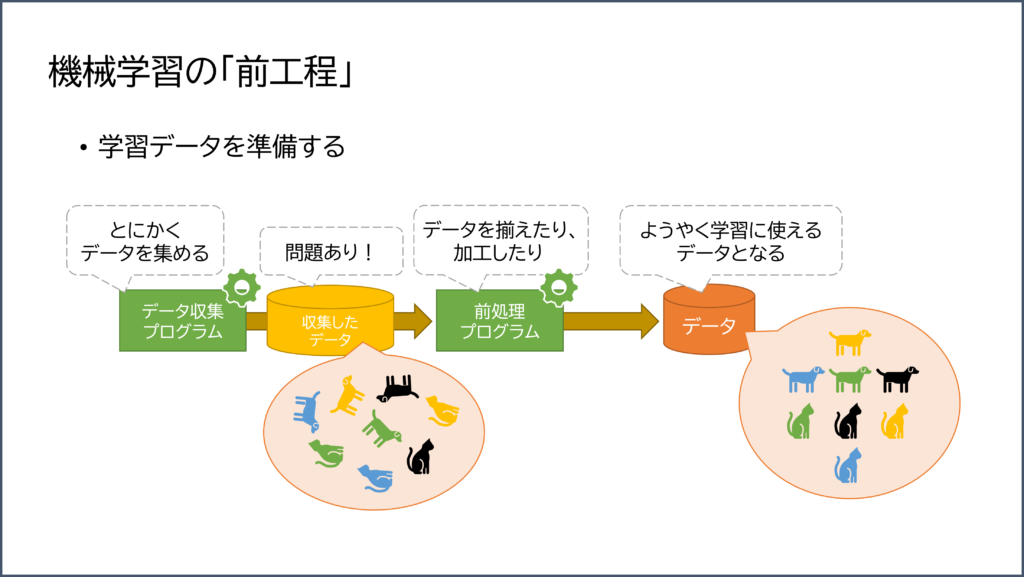
データは「ただ多ければ良い」というわけではなく、「適切」である必要があります。
例えば、犬の画像を集めたとき、それが正面だったり後ろ姿だったり寝ていたりするものを全てまとめて「犬の画像」とはしません。
「これは正面の犬の画像」「これは横から見た犬の画像」というように分類したり、
「一枚の画像の中には一匹だけ収まるようにサイズを調整する」という加工が必要です。
そのように、適切に加工されたデータがあって初めて「学習」することができるのです。
機械学習プログラムの流れ
実際に、どのようにプログラムが動くのかを図解します。
なお、この例では「犬と猫の画像」を学習したルールを予測プログラムに入れ、未知のデータとして「猫」の画像を判別させると「猫である」と判定される流れになっています。
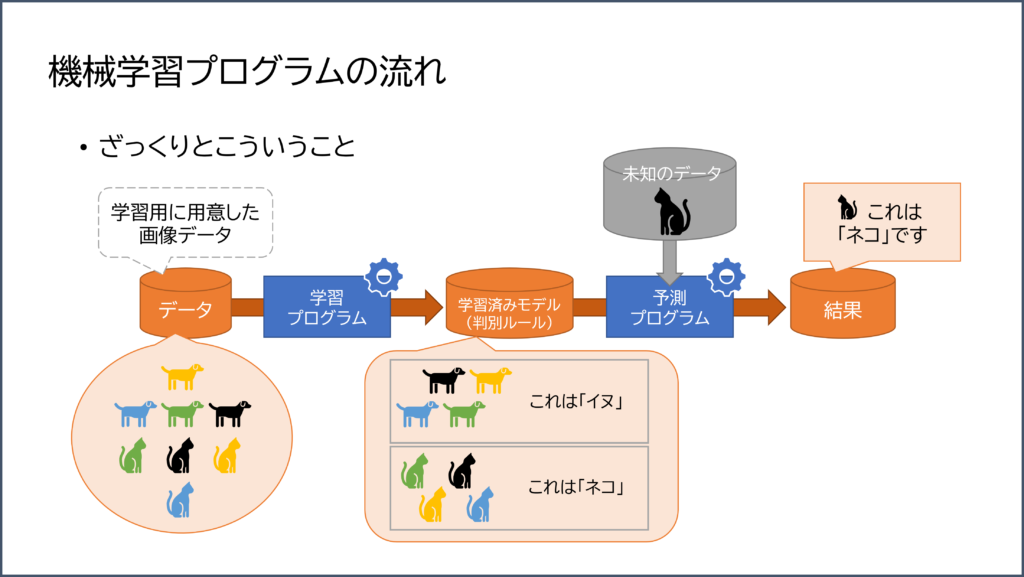
前工程で用意した画像データに基づき、学習プログラムを作成。
そこでできた判別ルール(モデル)を使って予測プログラムを実行し、画像や動画を判定しています。
あくまで一例ですが、このように処理されています。
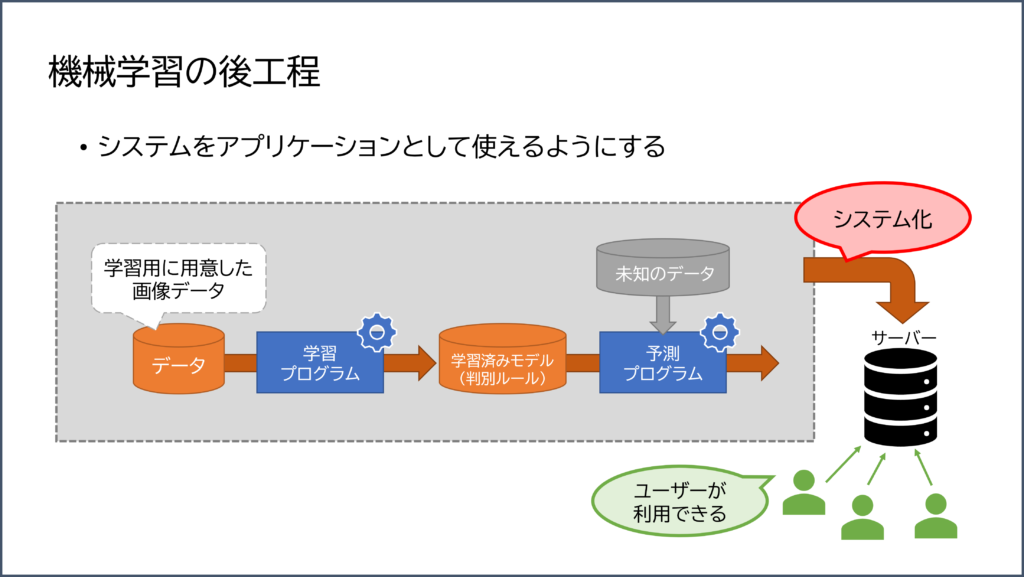
機械学習の後工程
細かい話ですが、AI のシステムをユーザーが利用するために「システム化」する必要があります。
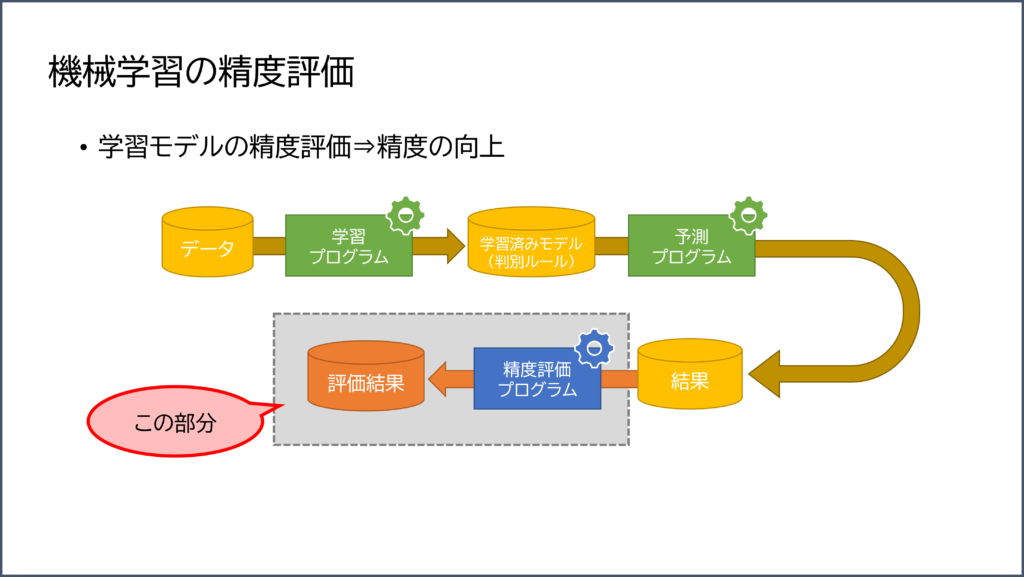
機械学習の精度評価
補足となりますが、データが適切だったか?アルゴリズムの選択は正しかったか?パラメータの調整は?など、実際にそのシステムの精度を確認する必要があります。
最後のその流れを図解します。
これ以上の詳しい説明は不要かと思いますので、以上で終わります。
まとめ
今回はAI(人工知能)に関連する技術の全体像が「ざっくり」と解説しました。
少しでもイメージが掴めたという人がいれば幸いです。
他にも何か質問や疑問がある場合はフォームやコメントでお知らせください。
Pythonについて詳しく知りたいという方は、こちらの書籍もおススメです。
それでは、ステキなPythonライフを!





